al=0x132020-11-25T05:18:51.000Zhttps://modethirteen.com/James Andrew Vaughn (Andy)HexoInterfaces for Humans on an API-First Platformhttps://modethirteen.com/2020/04/20/interfaces-for-humans-on-an-api-first-platform/2020-04-21T02:35:45.000Z2020-11-25T05:18:51.000Z
Update 2020-11-21: I particularly enjoyed this post by Martin Tournoij. I think he captures the type of empathy for developers that I struggled to express to the revenue-driven side of our business before I invested in my product management chops. Poorly designed and documented APIs contribute to (though are not entirely the cause of) poorly executed integrations - which is surely felt when they add risk to strategic partnerships. Back to regularly scheduled programming…
During my time at MindTouch, the early design decision to build an API-first platform has yielded some amazing technical gains that I benefited from as a software architect, but also some real pains that I experienced years later as a technical product manager positioning the same API for partner developers and system integrators.
Steve Bjorg, Founder/CTO of MindTouch, explained the decisions around API-first in 2007…
In 2019, one of MindTouch’s principal engineers, Juan Torres, elaborated on the downstream benefits of MindTouch’s event-driven service model, which benefits greatly from Steve’s original API-first vision…
Steve’s original concept, combined with MindTouch’s strong open-source friendly outlook at the time, were the core reasons I joined the organization. However, as the years progressed and MindTouch began to reposition itself for more turn-key use cases, I sensed a lack of ownership over the developer experience, as IT system admin and integrator personas and needs lacked strong understanding or empathy from our organization. As a result, our engineers added new functionality to the shared API simply to facilitate the creation of new features in the product experience, with neither them nor product managers considering how these APIs could be leveraged directly to create value.
When I took on the challenge of positioning the API to solve partner and B2B customer integration problems, I found that years of neglect had led to poorly maintained documentation and inconsistency across API input parameters and response data structure patterns. API endpoints that were clearly only created for internal DevOps needs were publicly exposed. Access to these endpoints was fortunately controlled, but still resulted in a confusing experience for partner developers.
Unfortunately, due to lock-in with our proprietary RESTful API framework, we lacked some of the “auto-documenting” capabilities of tools like Swagger. After building similar capabilities into our framework, it was time to enforce some sort of standard for API visibility and documentation. I wrote and shared the following document with our engineering team to reintroduce this discipline. I’m sharing this document publicly to demonstrate a level of control a product manager may need to place on the interface, to provide a consistent documentation experience. After API parameters and descriptions are documented consistently and intuitively, the natural next step is to apply standards (possibly in the form of a design spec) on the input and output data structures themselves.
A UI/UX designer considers intuitiveness and consistency with their approach with graphical user interfaces, why not take the same approach with a developer’s interface, an API?
API Feature Development
As a product capability, the public API requires consistency in its presentation to customers and partner developers. Following these conventions and best practices ensures that the public API documentation and experience will remain consistently high quality.
API Visibility
All new API features (endpoints) are initially created in one of two allowed states: hidden or internal. Neither hidden nor internal features appear in API documentation. Depending on how permissions are checked, hidden features can be accessible by any user type or role, whereas internal features can only be access by customer site administrators or internal MindTouch staff.
With few exceptions, new features require token validation and include an attribute to ensure that all sites enforce this behavior on these features. This includes older sites that do not yet have token validation enforcement enabled as the default behavior for all API features.
Some internal features are intended to only be used by Engineering, DevOps, and Support whilst on the MindTouch employee network or VPN. These features are marked as trusted internal features with an attribute.
// Hidden features have a public visibility keyword, so that they can // be accessed by non-administrators in user experience, however the // feature remains hidden in API documentation until it is reviewed by // the API product manager. [DreamFeature("GET:widgets", "Retrieve list of widgets", Hidden = true)]
// Here is the one use case for disabling authorization or API token // enforcement: downloading log reports, images, file attachments, etc. // Browsers download these resources as media files and will not send // authorization if the user is anonymous. [DreamFeature("GET:files/{filename}", "Download file")] [DreamFeature("GET:users.csv", "Download list of users")] [TokenNotRequiredFeature] public DreamMessage GetFile(IAttachmentsBL attachmentsBL) { }
// Internal features have a internal visibility keyword and can only be // accessed by internal MindTouch staff or customer site administrators. // Internal features are intended to never be visible in API documentation. [DreamFeature("PUT:site", "Destroy a site")]
// Add this attribute if the internal feature is intended by used internally // by DevOps [TrustedInternalFeature] internal DreamMessage PutSite(INukeBL nukeBL) { }
API Feature Descriptions
API descriptions use common semantics and phrases to articulate what they are used for. While these are the general rule of thumb, exceptions can be made for XML-RPC style features (move, copy, etc), that do not follow RESTful conventions. As necessary with any product messaging, the API product manager will assist you in providing the correct phrasing and tone.
// GET features "retrieve" resources. // A feature that retrieves more than one resource, retrieves a "list". [DreamFeature("GET:widgets", "Retrieve list of widgets")] [DreamFeature("GET:widget/{id}", "Retrieve widget")]
// GET features "download" resources if they have a // "Content-Disposition" header [DreamFeature("GET:files/{filename}", "Download file")] [DreamFeature("GET:users.csv", "Download list of users")]
// PUT features "update" a resource. // The resource is never prefixed with an article ("a", "an", "the"). [DreamFeature("PUT:widgets/{id}", "Update widget")]
// POST features "create" or "create or update" a resource // (depending on the behavior of the method). // The resource is never prefixed with an article ("a", "an", "the"). [DreamFeature("POST:widgets", "Create widget")] [DreamFeature("POST:widgets", "Create or update widget")]
// DELETE features "remove" a resource. // The resource is never prefixed with an article ("a", "an", "the"). [DreamFeature("DELETE:widgets/{id}", "Remove widget")]
API Feature Parameters
API feature parameters also require consistency in phrasing and tone. Several parameters such as {pageid}, {fileid}, {userid}, and {groupid} are reused through different features, and are resolved from the request in a common way (ex: pageid can be an integer, “home”, a = prefixed title, or a : prefixed GUID).
// there are constant descriptions for common parameters [DreamFeatureParam("{pageid}", "string", PARAM_PAGEID_DESCRIPTION)] [DreamFeatureParam("{filename}", "string", PARAM_FILENAME_DESCRIPTION)]
// parameter descriptions never end with a "." character [DreamFeatureParam("description", "string?", "File attachment description")]
// default values on optional values are expressed with (default: {value}) [DreamFeatureParam( "limit", "int?", "File attachment download size limit (default: 2048)" )]
Obsolete API Features
Obsoleting a feature means either a different feature should be used, or the feature is sunsetted entirely. Marking a feature obsolete has the same effect as hiding it, so the Hidden property is redundant.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// directing users to a new feature is expressed by "Use {feature}" in // the Obsolete property. [DreamFeature( "GET:site/widgets", "Retrieve list of widgets", Obsolete = "Use GET:widgets" )]
// the method for a sunsetted feature is also marked with an // ObsoleteAttribute, and an API product manager approved sunset // message is set in the Obsolete property. [Obsolete] [DreamFeature( "GET:widgets", "Retrieve list of widgets", Obsolete = "Widgets have been sunsetted are no longer available" )]
]]>APIs are for people too, so let's stop treating developers like machines.You May Not Need Service Discoveryhttps://modethirteen.com/2019/12/23/you-may-not-need-service-discovery/2019-12-24T02:46:30.000Z2020-11-05T19:06:55.000Z
As modern application architecture is decoupled more and more into independently running services, we’re all once again experiencing the pains that some of us remember from the SOA days in the early 2000s. A popular saying in software engineering is that the two hardest problems in computer science are:
Cache invalidation
Naming things
…and then everyone typically adds a third problem, based on whatever particular stress they are going through at that very moment:
As of this year, my “number three” on the list is:
Constantly having to remind myself that in-memory communication between software components is always easier than over the wire
My inner-voice is there to convince me that breaking a component off of the monolith (that component being what we are all calling a microservice now) probably introduces a range of new problems that can overshadow the original perceived value of decomposing the application in the first place. Even load-balanced monolithic application servers have SOA-like problems that are still there even if the monolith goes away. At MindTouch, we ran into one that had been hiding in plain sight for nearly a decade.
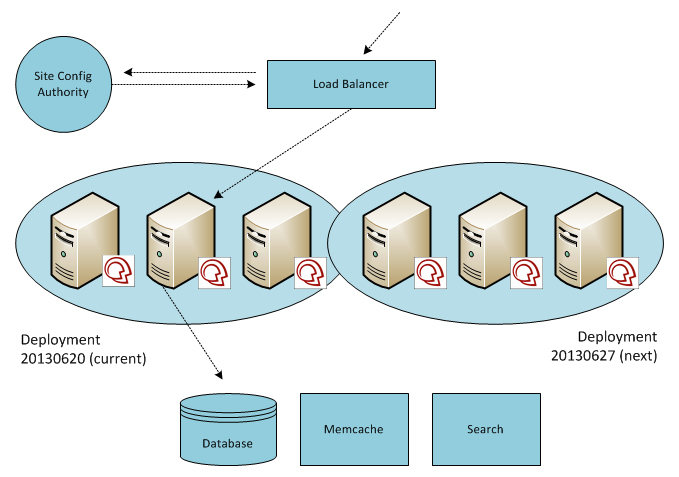
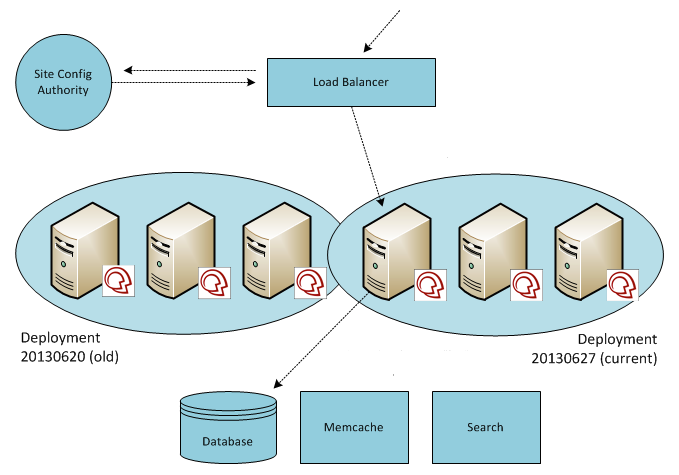
We’ve used a progressiveblue-green deployment for many years to release new software on our shared, multi-tenant SaaS infrastructure. The approach is progressive in-so-far that tenants are switched to new software in batches (to monitor for problems and lessen their impact) as opposed to flipping a switch for all tenants at once.
Tenants are identified by hostname (ex: foo.mindtouch.us, bar.mindtouch.us, etc). Incoming requests are routed to the appropriate pool of EC2-hosted application servers for the requested tenant. If a blue-green deployment is in progress, and the tenant is queued to switch to the new software release but has not yet been moved over to it, the load balancer can still route correctly. This is due to the presence of a site configuration authority: a centralized database of all tenants and their deployments, plus an internal tenant manager application that writes to this database. Deployments are simply a list of EC2 IP addresses that represent the application servers in a particular pool.
Blue-green can certainly mitigate risk in this “load-balanced application server” architecture. Any software update, regardless of whatever model or methodology you use, will always introduce risk. This particular approach makes it tolerable for us and our users. Due to the requirements that we had when standing up this infrastructure, we chose HAProxy over Amazon’s native load balancer. This meant that while we could place these application servers in auto-scaling groups, there wouldn’t be any benefit if our load balancer of choice and our home-grown deployment model couldn’t take advantage of it. If our service ever came under heavy load, we would have to spin-up EC2s manually, provision them with all the requirements to run our software (and install the application software itself) using Puppet, then add the EC2 IP address to the application server pool for the live deployment. Historically, this was required so infrequently that automating these steps didn’t seem necessary.
Until we had a real SaaS business going…
This year we completed a migration of all application servers and event-driven microservices to containers hosted on Amazon EKS (k8s). The many reasons behind the switch are deserving of a case study, but the key point that’s relevant to this post is that we could quickly auto-scale application servers (now in k8s pods) and it was becoming necessary to do so. As an added benefit, all load balancing between deployments could be managed within k8s, making the old deployment model of static IP address lists obsolete.
There was one big problem. The fore-mentioned internal tenant manager can restart tenants - which is required for certain kinds of configuration changes. Each application server, in every container, keeps an in-memory record of the configurations for every tenant that it’s had to serve. Keeping an in-memory copy allows any application server to quickly handle a request for any tenant (so specific tenants need not be pegged to specific containers). In order to restart a tenant, the tenant manager would send a restart HTTP payload to an internal API endpoint on each application server. With k8s managing and auto-scaling all containers, this application had no idea which IP addresses to target - effectively breaking this capability.
We need service discovery!
The faulty assumption, out of the gate, is that this tenant manager still needs to know where the downstream application is running. When faced with challenges, we can often gravitate towards what is known or what we are comfortable with. We presume that other options are going to be difficult to achieve. Why not? We obviously chose the simplest option when we first built this! With that presumption in place, we are likely ignoring an even simpler and possibly more elegant solution - because in the last few years we’ve become smarter and better at our craft.
All the tenant manager needs to know about is one location: where to write a big message on the side of a wall for someone to read later. The message is for any application server that reads it to restart a specific tenant - and every application server knows to check the wall before handling an incoming request, just in case there is new information about the intended tenant for the request. We implemented this with a distributed lifecycle token.
A distributed lifecycle token is an arbitrary value stored in an authoritative location that downstream applications and services can use to detect upstream changes. If downstream components store the value of the token and later detect that their stored value no longer matches the authoritative source, they can infer some sort of meaning from that. In our use case, they know that the tenant manager has requested the restart of a tenant. Allowing downstream components to eventually take action on, or be triggered by, a write to a data store, an event stream, or a similar authoritative location is a great example of event-driven and reactive programming in use.
First, we need a connection to a centralized, in-memory data store (such as Memcached, Redis, etc.) that can be accessed by any application server. Any tokens in this data store need to contain some sort of tenant-specific context. The following example is not meant to be representative of a full-featured Memcached client, but rather the minimum required to demonstrate this implementation.
// we have an internal utility for generating random memcache-friendly key strings, // point is, make the key safe and unique return key + ":" + StringUtil.CreateAlphaNumericKey(8); }
Next, we wrap our general-purpose distributed token logic in an easy to call utility. We can use this both in the tenant manager as well as the downstream application servers.
Instead of sending an HTTP payload to different IP addresses in a pool of application servers, now the tenant manager simply does this:
1 2 3
var tenantId = '12345'; var lifecycleProvider = new TenantLifecycleTokenProvider(_tokenFactory.NewDistributedTokenProvider(tenantId)); lifecycleProvider.InitToken();
A downstream application server, when it handles an incoming request for a tenant, first checks if it can lookup an in-memory copy of the tenant’s configuration. If not, it fetches it from the site configuration authority and looks up the tenant’s lifecycle token. If the lifecycle token for this tenant is not yet initialized (it may not have been if the tenant manager didn’t need to restart the tenant), then the application server initialize it, so that other application servers in the pool can know the current lifecycle state of the tenant.
1 2 3 4 5 6 7 8
var tenantId = '12345'; var tenantConfiguration = siteConfigurationAuthorityConnector.getTenantConfiguration(tenantId); var lifecycleToken = lifecycleTokenProvider.GetToken(); if(lifecycleToken == null) { lifecycleToken = lifecycleTokenProvider.InitToken(); } var tenant = new Tenant(tenantConfiguration, lifecycleToken); tenants.Add(tenant.Id, tenant);
When handling an incoming request, the application server checks if the tenant needs to be restarted before fulfilling the request. If the distributed lifecycle token has changed since we last read it and no longer matches the tenant’s lifecycle token, we know that the tenant manager is asking for a tenant restart.
1 2 3 4 5 6
var tenantId = '12345'; var tenant = tenant.Get(tenantId); var lifecycleToken = lifecycleTokenProvider.GetToken(); if(tenant.LifecycleToken != lifecycleToken) { tenant = null; }
In our particular architecture, nullifying the tenant at this stage triggers the application server to instantiate a new Tenant object and register it in the lookup, as seen above. This process is repeated for all application servers. The addition or reduction of containers or pods does not affect the tenant manager’s ability to restart tenants.
I am absolutely not a critic of service discovery in principal. When necessary to facilitate direct communication with components on a network, it can be a life-saver. However, if your use case does not require direct communication and eventual consistency among downstream data, and application state is acceptable for your use case, consider reactive programming solutions. Everything will be ok (eventually)!
…and if it’s not, you can always deploy systems to handle those situations out-of-band:
]]>A consideration for distributed lifecycle tokens...Impact Mapping with Graphvizhttps://modethirteen.com/2019/10/16/impact-mapping-with-graphviz/2019-10-16T20:12:10.000Z2020-12-01T05:45:00.000Z
So I’ve turned on terminator vision lately while I try to locate the absolute unicorn of opportunities to prioritize in our product backlog. I’ve turned this into a borderline obsession now, after reading Kathy Sierra’s Badass: Making Users Awesome. What is the absolutely smallest improvement that can have the greatest impact?
No, really, WHAT IS IT?!
A colleague of mine recently turned me onto a process that potentially gets me closer to that answer: Impact Mapping. I’ll let the creator, Gojko Adzic, explain the process in detail in his highly recommended book. The key factor here is that the collaborative process involves building a graph or a tree from which the smallest yet most impactful items can be recognized. In other words, you can visualize what is valuable and very importantly, things that are not. Suddenly, everyone sees the loudest and most highly paid individual’s “must-have” idea orphaned on a dead tree branch with wilting leaves. The concept of graphing value as dependencies (because I live for scalable dependency management) is highly appealing to the engineer in me since my IDE these days is Google Slides 🙄.
Without getting too deep into the methodology of drawing impact maps, let’s state that the map starts with a measurable product or company objective. The next level down includes the actors: the direct practitioners or indirect influencers that affect this goal, what actions they perform or impact that is created through their behavior, and what we need to deliver to enable (or in some cases secure against) those impacts.
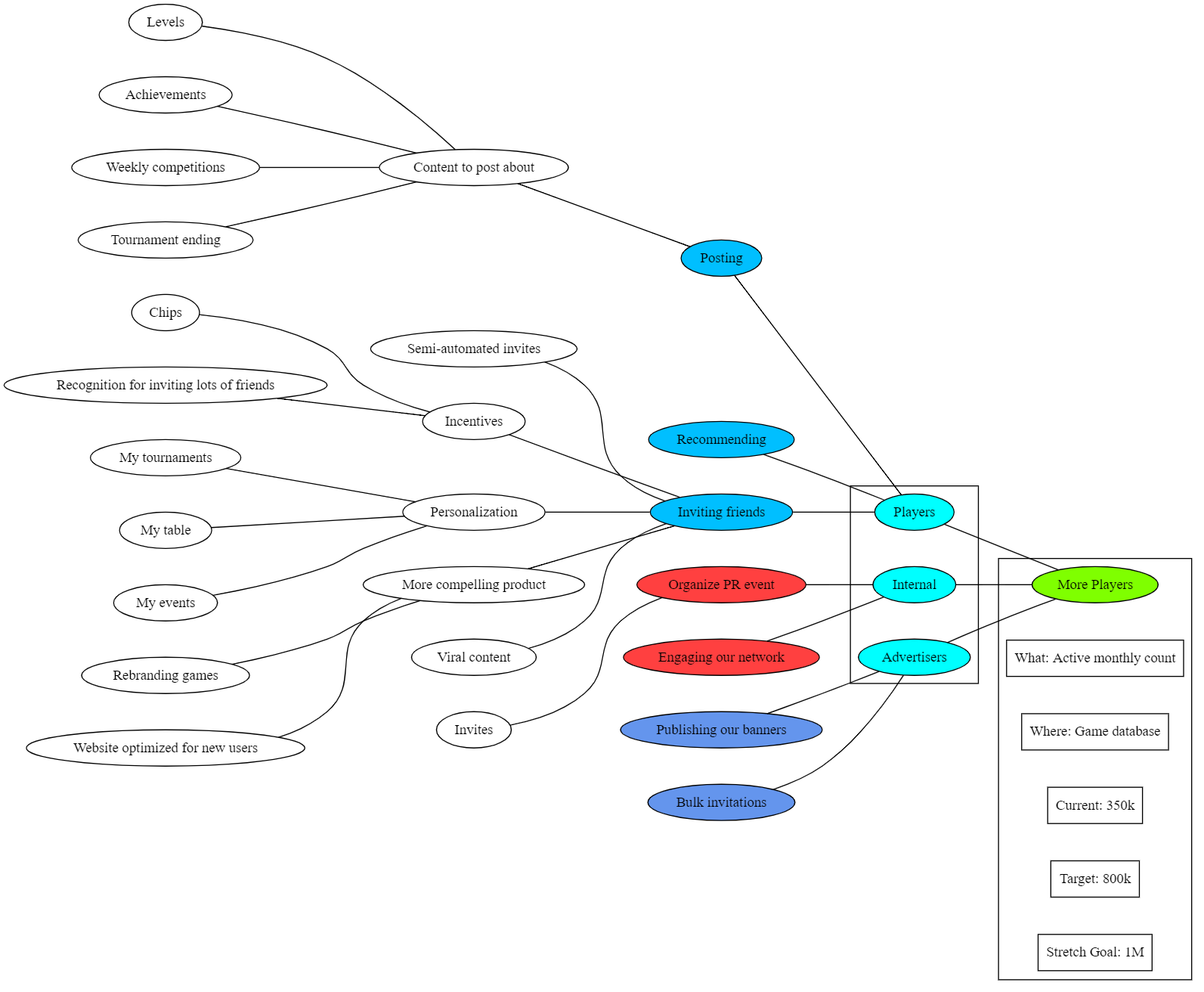
Great - here is a possible impact map (using an example from the book), with success measurements, in Graphviz-compatibledot format:
// What are all the impacts that an advertiser can make? subgraph AdvertiserImpacts { node [style=filled, fillcolor=cornflowerblue] "Advertisers" -- { "Publishing our banners" "Bulk invitations" } }
// What are all the impacts that internal staff can make? subgraph AdvertiserImpacts { node [style=filled, fillcolor=brown1] "Internal" -- { "Organize PR event" "Engaging our network" } }
// What are all the impacts that a player can take? subgraph PlayerImpacts { node [style=filled, fillcolor=deepskyblue] "Players" -- { "Posting" "Recommending" "Inviting friends" } }
// Which deliverables exist to organize events? subgraph AdvertiserOrganizeEventOpportunities { "Organize PR event" -- "Invites" }
// Which deliverables impact the player posting experience? subgraph PlayerPostingOpportunities { "Posting" -- "Content to post about" "Content to post about" -- { "Levels" "Achievements" "Weekly competitions" "Tournament ending" } }
// Which deliverables impact the player invitation experience? subgraph PlayerInviteFriendsOpportunities { "Inviting friends" -- { "Semi-automated invites" "Incentives" "Personalization" "More compelling product" "Viral content" } "Incentives" -- { "Chips" "Recognition for inviting lots of friends" } "Personalization" -- { "My tournaments" "My table" "My events" } "More compelling product" -- { "Rebranding games" "Website optimized for new users" } } }
…and here is the rendered graph. The dot file can be checked into a project repository as source code, to be updated if new information is received or requirements change.
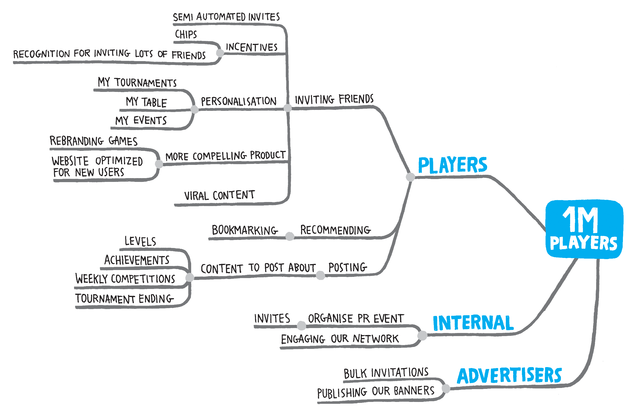
Obviously, more work can go into arranging the components for a more pleasing layout, such as the example provided by the author:
…but I hope to continue exploring this Graphviz use case to further the application of structured data visualization to product management tooling.
]]>I took a collaborative product planning technique and of course had to formalize it with code...Cryptography 101https://modethirteen.com/2019/06/07/cryptography-101/2019-06-08T03:44:19.000Z2020-12-04T05:21:53.540ZAt the end of every two-week MindTouch Engineering sprint, Patty Ramert hosts Last Sprint Today: a chance for us to share with other MindTouchers what we’ve learned, anything we are working on, or any technical topic of interest. This week, I presented an introduction to basic Cryptography, with some specific emphasis put on authorization and authentication flows.]]>The basics of hashing, signing, and encrypting data...What Can Apache Events and Workers Do for You?https://modethirteen.com/2019/03/10/what-can-apache-events-and-workers-do-for-you/2019-03-10T22:23:30.000Z2020-11-27T23:06:27.000Z
There are too many to count articles about configuring Apache or NGINX to optimize for multi-process, multi-threaded scenarios with one or more downstream, detached processors of HTTP requests (PHP-FPM, Passenger, ASP.NET, etc.). This post won’t be addressing the step-by-step configuration details. The key takeaway from most articles, that’s relevant here, is that it is often very taxing on high-load, performance-critical web servers when all possible request handlers and processors are engaged to satisfy every incoming client request - regardless of context. For example, a web server process doesn’t needruby to load a static JavaScript file off disk.
Due to MindTouch‘s evolution from delivering downloadable packages for on-premise installs to handling deployment ourselves in a SaaS model, decisions regarding how a web server should be configured to best run our platform were not made by us in the early days. We adopted what seemed to be the most common way to run PHP (our middleware web layout application) with Apache: the Apache Prefork MPM (Multi-Processing Model) with the mod_php module. Preforking is quite nice and straightforward for serving HTML and static resources such as JavaScript, CSS, and images. With the addition of mod_php, every web server process that is forked from the main process has all the tools it needs to handle any supported incoming requests.
MindTouch also had a unique requirement: a mono (.NET) hosted API host with its own rules for handling incoming requests. We used mod_proxy to direct traffic for a specific path segment to that downstream request handler.
…and this is how things probably would have remained if it wasn’t for this eventual problem:
Update 2020-11-27: It is worth mentioning that MindTouch now deploys these components as containers on Amazon EKS (k8s). When this post was written, all components described ran on EC2 application servers (with every application server configured with the same components).
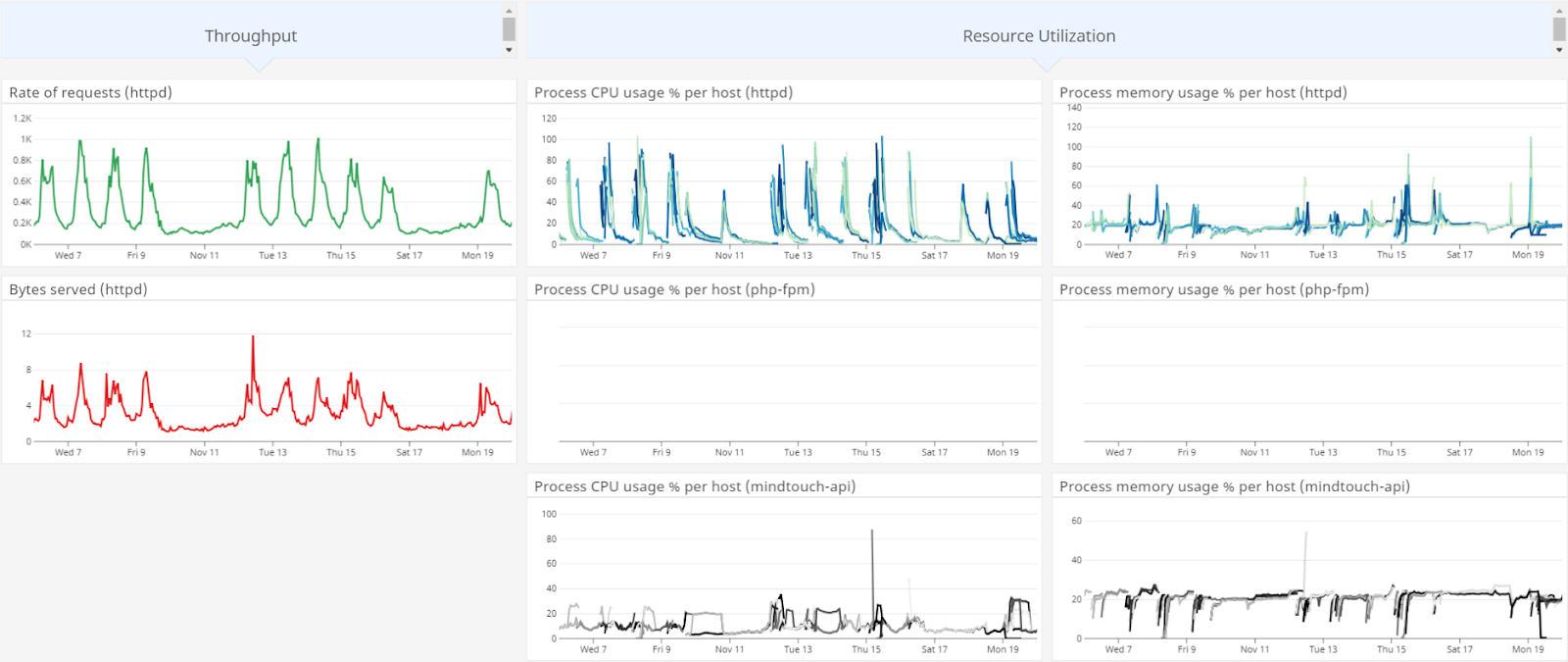
Yes, on an average day, while our core API processes required less than 40% of available resources, httpd (with its bulky PHP add-on) spiked and was often CPU-bound. We analyzed traffic and found that we were loading the entire PHP interpreter to handle PHP-unnecessary requests such as images, JavaScript, and the API. We quickly realized we were not being particularly efficient with our compute resources. Much of our asset delivery was already handled through a content delivery network (CDN) as well, so we weren’t even getting the worst of it.
We chose to implement worker threads with the Event MPM for a leaner web server process. Our longer-term plans include an initiative to deploy our web server, PHP middleware, and API host on separately scalable units (likely containers), so breaking apart these components seemed like a step in achieving that goal as well. (Update 2020-11-27: Done!) MindTouch’s hands-on VP of Technology, Pete Erickson, was very instrumental in allowing me to execute these changes safely.
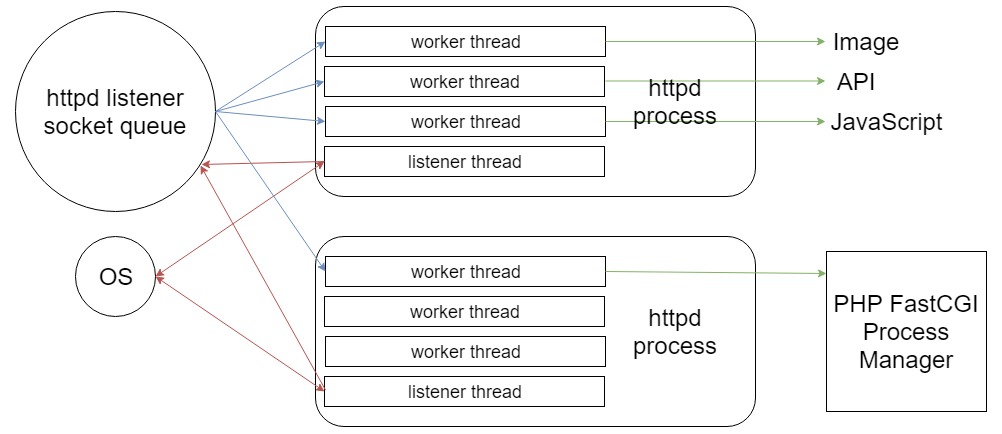
For a quick course in how threads operate in this context, I’ll do my best with the next few sentences (using the diagram above as a visual aid). The main web server process spawns child processes each with available worker threads and a single listener thread. The worker threads can be assigned to any incoming request received by the web server, and are expected to route the request to the appropriate downstream handler (the file system if fetching a static file, Fast CGI if another interpreter is necessary, etc.). This is already a much more efficient way to handle high rates of web traffic for different downstream destinations. However, the use of events and the listener thread makes this deployment fire on all cylinders.
Typically the worker thread would be bound to the web server socket, waiting for the downstream work to complete before returning some sort of response to the upstream client who originally sent the request. A CPU thread doesn’t need to sit around and do nothing while an operating system is trying to locate a file on disk, PHP is processing the received data, or the API is performing work. The listener thread listens for events fired from the main web server process socket queue of incoming requests and the operating system. It works with the process’s thread pool to determine when a worker thread needs to be called up to handle inbound or outbound communication for the webserver. If a request is presently being handled by a different process, there is no need for a web server thread to be tied up, and it can be available to handle incoming requests.
Incidentally, for you JavaScript enthusiasts, if this sounds a bit like concurrency as provided by the JavaScript Event Loop, it’s not 😛! While some similar benefits are realized in Node.js, such as non-blocking I/O, JavaScript achieves this by managing a single thread very well. In the example above, we are talking about a multi-threaded solution, which is a good use case to apply parallel computing.
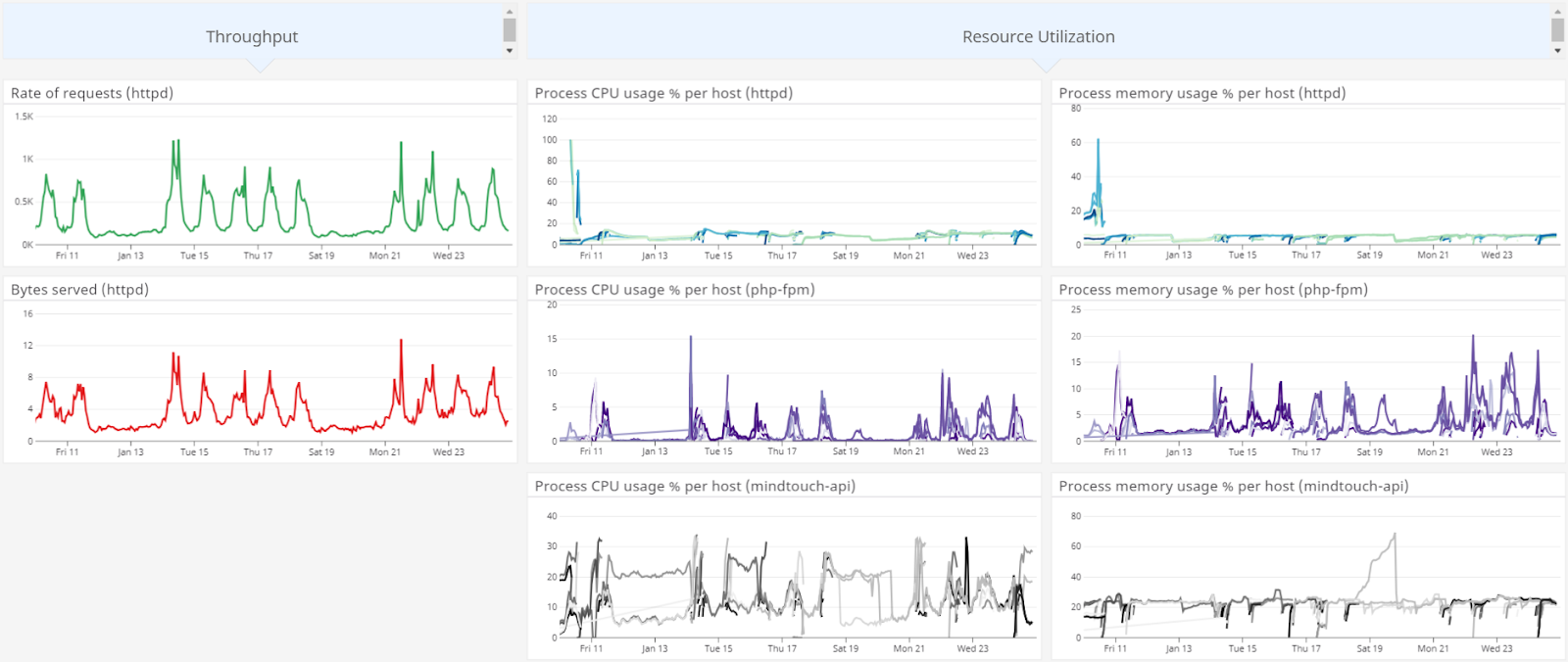
After tuning the number of child processes and threads, the outcome, with the same steady request rate, were significant:
We traded a collection of nearly CPU-bound Apache processes, for 15-20% utilization by PHP-FPM (the visualized “cliff” for the httpd processes represents when this change was fully rolled out to production servers). Getting the configuration right required a lot of testing and a lot of dead “canaries”, but the breathing room that we gained back led to a significantly more stable service for our customers (with more room for the occasional spike) and a much happier DevOps team!
]]>You can have your CPU and RAM back...Demystifying Authorization and Authentication Flowshttps://modethirteen.com/2019/01/25/demystifying-authorization-and-authentication-flows/2019-01-26T03:21:05.000Z2019-08-01T15:35:56.000ZUpdated 2019-08-01: In this video, I positioned the OAuth and OpenID Connect Implicit Flow as an implementation strategy for single-page web applications. Going forward, the new PKCE flow should be used for any new implementations involving public clients such as mobile applications and SPAs. Check out this Okta developer blog article for more details.
At the end of every two-week MindTouch Engineering sprint, Patty Ramert hosts Last Sprint Today: a chance for us to share with other MindTouchers what we’ve learned, anything we are working on, or any technical topic of interest. This week, I presented an introduction into the differences between three common authorization and authentication standards for Single Sign-On.
Slides:
]]>OAuth, OpenID Connect, and SAML: A basic primer...Witness the C64 MSSIAHhttps://modethirteen.com/2018/10/24/witness-the-c64-mssiah/2018-10-25T01:50:30.000Z2019-09-03T05:05:26.000ZThis is a vanity post, and a plug for one of the best pieces of hardware/software that I’ve ever purchased: the C64 MSSIAH cartridge. If you had any interest in the Elektron SidStation, or maybe noticed that Elektron spent the early 2000s acquiring every spare SID sound synthesis chip they could get their hands on, then check this out:
A few more videos like this, and I was hooked.
Once it arrived and I tried it with my original C64 (on the right), I was determined to track down another (well maintained, recapped, and tested) later-model C64 with an 8-pin audio/video DIN connector rather than the 5-pin connector on mine. For context, the 5-pin DIN is compatible with the type of composite video you would use with a television set in the 1980s (to play Moon Patrol, obviously). This was fine for my needs, as I acquired the machine (and a connector between 5-pin DIN and NTSC composite RCA) to play games from my childhood and forget that I turn 40 next year. The 8-pin connector is available on a C64 that supports a signal nearly equivalent to S-Video, and is supported by the official Commodore 1702 Video Monitor. The differences between the different ports are explained in more detail on the C64 wiki.
The odyssey to find a working 1702 Video Monitor that didn’t need a lot of work was pretty long, but I found one in great internal shape and mostly okay external shape (no major dents, scrapes, and just missing the panel that hides the video adjustment knobs). Both the monitor and the second, compatible, C64 are on the left.
And there is MSSIAH’s mono synthesizer, with the RCA cable (carrying the signal from the C64’s SID) into my DAW. MSSIAH is now a first-class citizen of my (small) home rig. I’ll post some results when I have the time to, you know, actually write music with all this stuff.
]]>It makes your SID vicious! (Editor's Note: Not funny, get out)The State of the Amiga 500 in 2018https://modethirteen.com/2018/10/18/the-state-of-the-amiga-500-in-2018/2018-10-18T21:46:30.000Z2019-02-03T19:17:26.000Z
It’s here! The machine I fell in love with as a teenager, though it was horribly misunderstood here in the United States. I found this clean, recapped Amiga 500 for the single purpose of installing a Vampire accelerator and turning it into a music tracking and sampling beast. If you aren’t familiar with the Vampire line of Amiga accelerators, they are based on the Apollo Core, which in turn is based on a CPU that is code-compatible with the Motorola 68k CPUs available in the 1990s, but roughly three to four times faster. The added benefits include jacked-up RAM and video capabilities as well (though it’s possible my tracking software won’t be able to take advantage of next-gen video). The M68k holds a special place in my heart, independent of its position as the Amiga 500 CPU, as it was the architecture that I first deep-dove into during my university days.
Presuming not all my Amiga software can take advantage of next-gen video and thus, the Vampire accelerator’s HDMI connector, one of the first problems out of the gate is that this is not an IBM PC, and VGA was not a cross-architecture standard between device manufacturers in the days of the Amiga 500. The Amiga 500 was designed with a proprietary RGB D-Sub connector to an Amiga video monitor. It took me long enough to find a C64 video monitor in working condition, so I wasn’t particularly interested in tracking down a working one for the Amiga.
Fortunately, many schematics exist for wiring the VGA pins to a DB23 connector. I used this one, though I couldn’t locate a DB23 connector. I ended up purchasing a DB25 and using a Dremel to slice off the extra two pins for a snug fit in the Amiga’s RGB port.
The pins were wired correctly, but then it was a matter of finding a VGA monitor that still supports 15 kHz analog RGB video signals. This is a video mode that is extinct from all modern computer monitors, and was already nearly extinct by the time flat panel (LCD) monitors became common. One option was to locate a CRT that supported it. The great irony is, from a price perspective, I found compatible CRTs to be more expensive than the compatible LCD that I chose, due to the recent high-demand for CRTs to recreate a retro-gaming experience (I’ve probably junked a comfortable retirement’s worth of CRTs in my lifetime).
This wiki helped me choose the NEC Multisync LCD1970NX. A flat panel was important due to space considerations in the eventual home studio build-out plan.
A MIDI connector, so that I could remotely start and stop the Amiga’s tracker in sync with Logic Pro X (on a separate MacBook Pro), was far less of a challenge to locate as plenty of parallel port-compatible DB25 MIDI I/O connectors are available on eBay or in various Amiga enthusiasts’ online shops. The same goes for a DB15 to USB connector for a modern mouse (I’m not exactly in love with the Amiga “tank mouse”). Be warned though, I had a lot of trouble with a wireless mouse behaving as expected. I ended up using a USB wired mouse with laser tracking.
Update 2019-02-03: The Vampire accelerator arrived! I plan to post a step-by-step of my experience installing it, a more “modern” version of AmigaOS, and wire up my tracker software to the rest of the studio.
]]>(Hint: It's still the best home computer ever made)The Demoscenehttps://modethirteen.com/2018/07/28/the-demoscene/2018-07-29T02:21:05.000Z2019-11-27T06:48:50.000ZUpdate 2020-11-26: Interesting companion piece I found from Motherboard (Vice) that touches on a point that I made about the lethargy of the North American Demoscene.
At the end of every two-week MindTouch Engineering sprint, Patty Ramert hosts Last Sprint Today: a chance for us to share with other MindTouchers what we’ve learned, anything we are working on, or any technical topic of interest. This week, I presented a primer on the Demoscene, which may be better described as “hackers gone wild” 😂.
Slides:
]]>How does a digital subculture develop?Introduction to the Chrome DevTools Protocolhttps://modethirteen.com/2018/04/07/introduction-to-the-chrome-devtools-protocol/2018-04-08T05:19:17.000Z2020-12-04T05:21:53.550ZAt the end of every two-week MindTouch Engineering sprint, Patty Ramert hosts Last Sprint Today: a chance for us to share with other MindTouchers what we’ve learned, anything we are working on, or any technical topic of interest. This week, I presented an introduction to the Chrome DevTools Protocol.
Here is the simple Puppeteer code that I used for the demo (checking CSS rule coverage on a webpage):
// output coverage report // (coverage data is likely in a different format than page.coverage) })();
]]>Automate your code inspections, debugging, and testing!Misadventures in Bundling Moduleshttps://modethirteen.com/2017/10/16/misadventures-in-bundling-modules/2017-10-17T03:39:18.000Z2020-12-04T05:21:53.550Z
If you are writing modular JavaScript source code using ES2015’s import keyword, you are likely transpiling your code so that it can execute in web browsers presently available to most users. As much as it is a pleasure to maintain your source code as modules, it’s been a bumpy road to reach a common implementation of modules in the JavaScript execution environments themselves, resulting in a rather large and confusing set of technologies. The problem described later requires a bit of knowledge about the relationship between UMD, AMD, and Require.JS. This post by David Calhoun gives a great overview.
An embeddable widget library, that our team develops and maintains, bundles the source JavaScript to simplify delivery to developers and integrators who rely on the library to embed in their websites. We didn’t notice that we had bundled them using UMD (Universal Module Definition) syntax. This led to problems when the library was added web applications leveraging the AMD syntax, like those depending on Require.JS. Transpiling to UMD included window.require as part of our bundle, leading to conflicts with the DOM’s window.require defined by the AMD-powered web application.
We corrected our mistake by transpiling to a global format. A word of caution: be careful when transpiling module syntax as there are many options for the target output. If you don’t have control over the webpage in which your code will execute (such as the case of an embeddable widget library), it’s wise to consider plain-old globals.
]]>Native ES2015 module browser support can't come soon enough.Walmart Lab's Women In Tech Hackathonhttps://modethirteen.com/2017/08/15/walmart-labs-women-in-tech-hackathon/2017-08-15T18:27:38.000Z2020-12-04T05:21:53.555ZI was honored to co-host the @WalmartLabs hackathon this past weekend. @WalmartLabs is the e-commerce technology arm of the largest retailer in the United States. Being an unabashed supporter of organizations like FC St. Pauli, it’s only natural that some may view my association here as questionable or perhaps even hypocritical. I likely would not have been overly enthusiastic about the arrangement if it wasn’t for the fact that it was executed by a strong group of women engineers within Walmart Labs. Don’t let achieving perfection of global economic equity be the enemy of great recruiting opportunities for a historically marginalized gender in the tech space 😉. No organization is perfect, but from what I’ve observed, and learned since the hackathon, @WalmartLabs actually executes on the promises of inclusion that so many companies in our space continue to profess.
Hackathons aren’t easy to pull off - and it’s important not to try to do too much. If the event is focused on promoting or leveraging specific tools (this particular event was promoting @WalmartLabs Electrode React/Node.js framework), familiarity and training with the tools before a competition is underway is a must-have. For those of you planning an event, consider a scripted challenge with a clear result or outcome to achieve, using the promoted technology. Future hackathons, with increasingly more breadth and positioned to developers that develop mastery of the chosen technology, can build a dedicated community and strong advocates for the tech in the industry.
]]>An insightful day of innovation and collaboration...#KANMFhttps://modethirteen.com/2016/08/31/kanmf/2016-08-31T22:41:05.000Z2019-11-14T02:14:53.000Z“#KANMF” entered the MindTouch lexicon last year as an unofficial company motto (along with our “no douchebags” policy):
Kick
Ass
Ninja
Mother
Fu…
…you get the idea. MindTouch has operated very lean for quite some time, and has always tried to hire people that help the organization punch above its weight class: those that see the limits on money, time, and resources as a challenge to get the blood pumping. I’ve had the occasional run-in with former technical colleagues that moved on to more established firms (Apple, Google, etc), and the common (paraphrased) refrain is this: “the results may not yet be exposed to the widest audience, but I did the best work of my career when I had to perform like a code ninja - gaining mastery across the entire surface area of the platform”. Point is, if that’s what you are looking for, you probably aren’t going to find it in big tech.
Some of the sales staff ran with the ninja concept and long story short, now we have swords 🙄. As playful as it is, I do have somewhat mixed feelings about these weapons knocking about the office, without at least a demonstration of how dangerous they can be. I’ve trained with, and taught at, Pacific Martial Arts, for many years, with Shindō Musō-ryū as a significant focus during the last several (I’m very much still an amateur with the bokken):
Update 2019-11-13: I had the opportunity to demonstrate Shindo recently, giving it the level of decorum that a martial art deserves:
]]>Swords in the office, what could go wrong?Tear It Down, Build It Back Up: Infrastructure as Codehttps://modethirteen.com/2015/05/31/tear-it-down-build-it-back-up-infrastructure-as-code/2015-06-01T05:30:20.000Z2020-12-04T05:21:53.551ZI recently gave a short talk on how we manage our AWS infrastructure as code at Gluecon 2015. Enjoy! …and despite the results, we did try our best with the audio!
Slides:
]]>If you really, really want to ssh to update your production servers, be my guest. For the rest of us...Fluent 2015https://modethirteen.com/2015/04/24/fluent-2015/2015-04-25T06:22:58.000Z2019-03-01T18:51:40.000Z
With the assistance of the Linux Foundation, io.js and Node.js will join a community-led and industry-backed consortium to lead the development of Node.js (essentially healing the fork)
We can all get along: Standard-bearers for io.js, Node.js, the Linux Foundation, me (because I’m awesome), and key industry leaders who rely on this ecosystem
React.js seems to be a proper application of the functional programming aspects of JavaScript that I actually like
Be an ES2015 (ES6) JavaScript module-first shop: developing and testing individual components is how real, big-boy codebases scale (transpile to global ES5 to deliver to today’s browsers, while developing for the future)
PHP takes further steps towards a Java-like syntax with PHP 7
Rasmus Lerdorf said that PHP for a thin data marshaling layer is good and bloated PHP apps are bad - completely agree!
]]>Quick takeaways from Fluent 2015...Continuous Delivery Without Breaking Everythinghttps://modethirteen.com/2014/11/10/continuous-delivery-without-breaking-everything/2014-11-10T18:16:15.000Z2020-11-27T20:36:15.000Z
Let’s start with one key fact: Continuous Delivery, though expanded from Continuous Integration, is not simply automating your code deployment pipeline like you automated your build architecture. Continuous Delivery is a shared business process, a contract between different members of product delivery to move software through stages to someone who will benefit, without blocking it or at best avoiding unreasonably long delays.
Automation applied to an inefficient operation will magnify the inefficiency.
Where were we ten years ago? At your organization, it probably looked something like this: long product release cycles leading to long development and testing cycles with lots and lots of value bundled up in massive code drops.
…followed by many smaller point releases to fix all the things that broke when you finally received validation from the real world - not just from internal testing or beta users. I’m sure it was really fun going back over six months of code to find the one change that broke the entire release 🙃.
This was MindTouch prior to 2012. We delivered software packages, available for system administrators to download and patch or upgrade our software running in data centers. Software-as-a-Service (SaaS) delivery became a near-term goal for us, as supporting our customers indirectly through their IT departments was becoming unmaintainable. We wrote the software, so we knew how best to deploy and run it!
However, long six-month development cycles were unsuitable for SaaS delivery and also under-leveraged one of the key business-benefits of SaaS: you can deliver value to your customers immediately.
Much of our software was not in an ideal state for the “high-speed, always merge to the main branch, the main branch is deployed to customers” style of software delivery. As a result, we approached SaaS development and delivery in a more cautious, though not entirely pure continuous model:
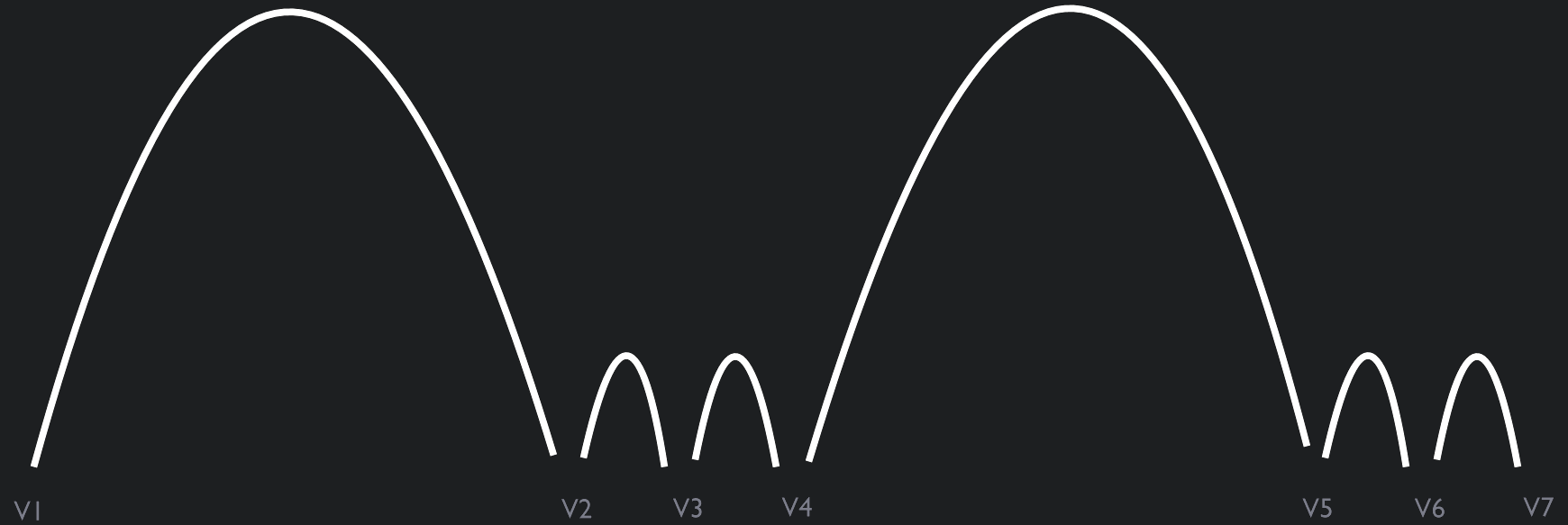
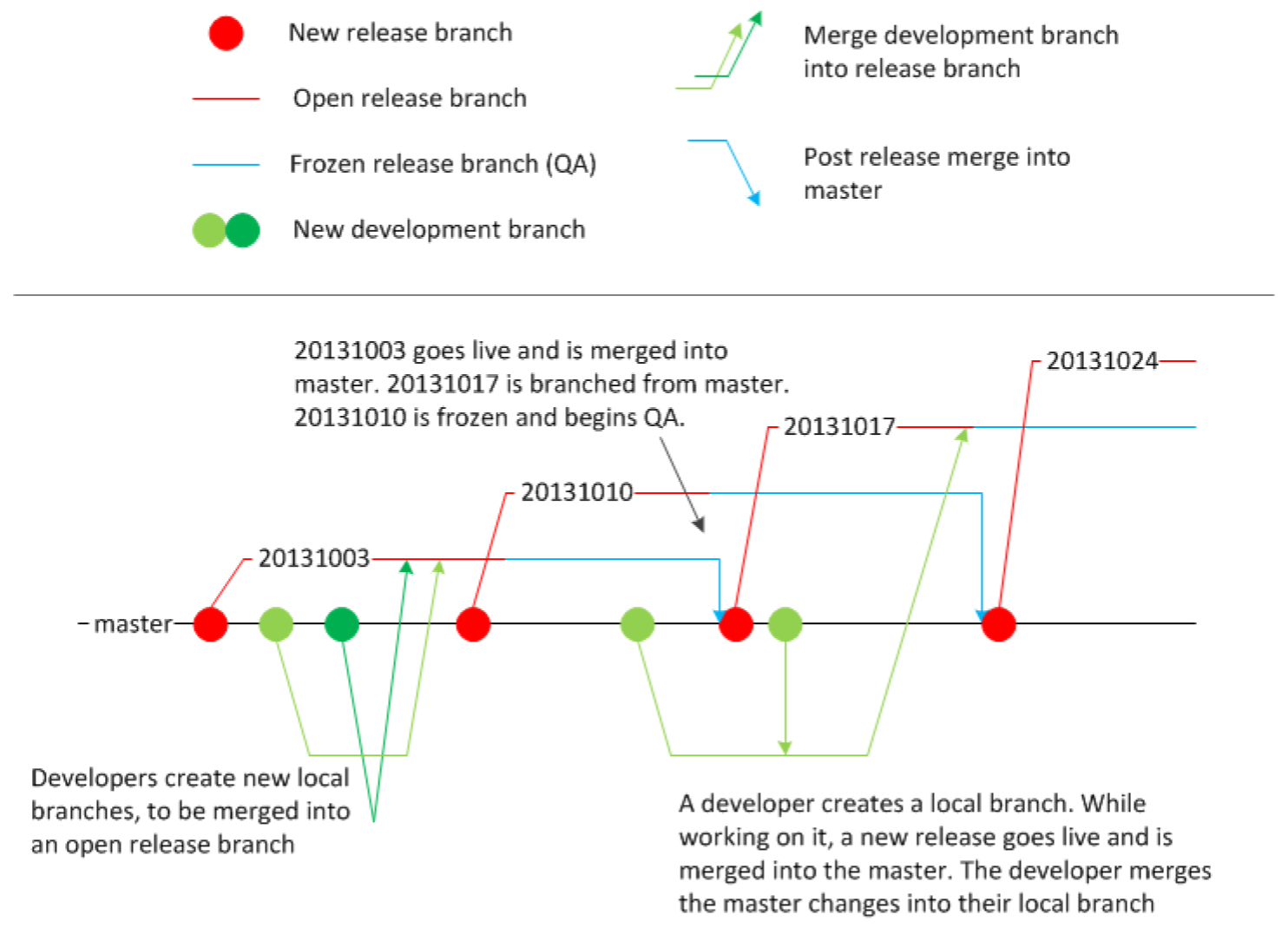
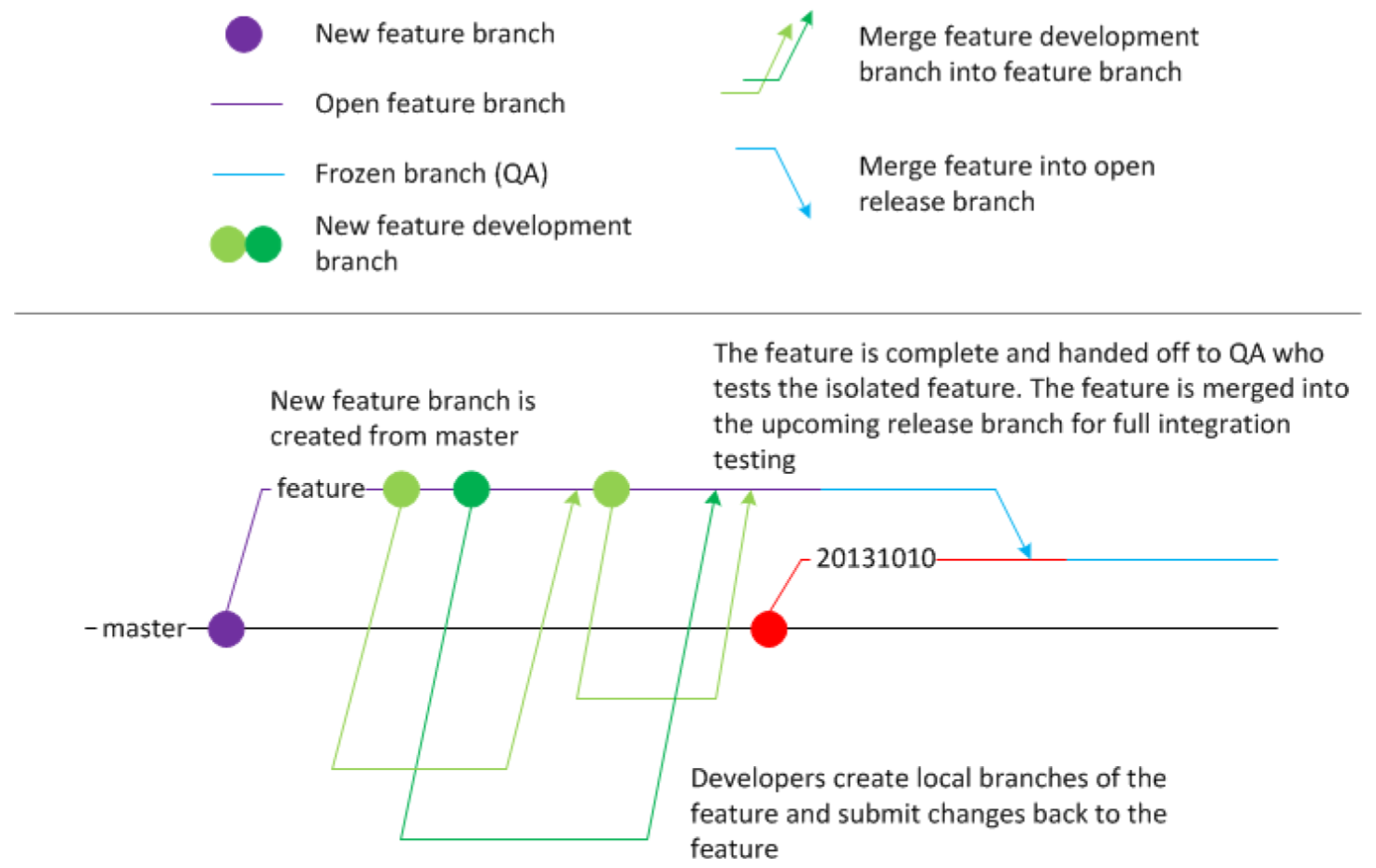
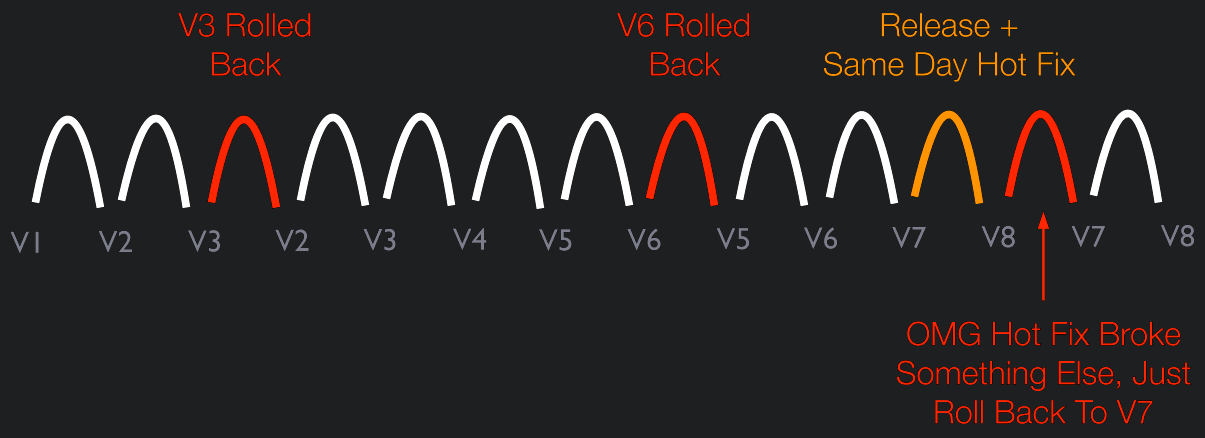
This is our current GitHub workflow. Yes, I know: Feature branches are not continuous. However, this is a transitional state for a codebase, which was until very recently tested end-to-end within six-month cycles, while its stabilized to be continuously delivered whenever it needs to be. For the time being, we’ve chosen weekly releases as our target. The immediate benefit achieved is a much smaller delta between changes resulting in quicker defect fixes (or rollbacks if necessary).
Rollbacks require that there is a previous feature branch or tag that we can rollback to - seemingly the antithesis of a continuous delivery process
Technically speaking, the long-term goal is to deliver value when it’s needed and not let the tools dictate when we can deliver.
A single branch that always flows into live production requires confidence that the process will be resilient as possible and can quickly deliver corrections to defects as well as new features or value
Test your Continuous Delivery process with humans first and make sure it works for how your organization needs to reliably deliver software today.
]]>What is CD and, especially, what is it not?Automocking Dependencieshttps://modethirteen.com/2014/02/25/automocking-dependencies/2014-02-25T18:57:45.000Z2020-11-26T17:36:18.000Z
I created OpenContainer to assist in the refactoring of legacy PHP code at MindTouch. The goal was to shore up the stability of the codebase as we transitioned from six-month waterfall-driven software delivery cycles to continuous delivery twice per week. While the majority of critical business logic was implemented and exposed via APIs in a C# codebase with (fairly) okay test coverage, PHP was used to marshall data from these APIs and deliver a product experience. There were two major challenges to achieving reasonable stability and reliability for the PHP codebase:
The codebase lacked any automated unit or integration testing
Nearly all code relied on static functions or global state, with no formalization in code of the relationship between dependencies
The latter situation, in particular, got under my skin. I’ve never particularly been a fan of dynamic or loosely typed languages (it bothers me that we are so quick to throw decades worth of type system research out the window for so-called flexibility). Just about every global variable that could be mutated from anywhere across the codebase was mutated, usually as side effects of seemingly unrelated routines. If code paths were going to be tested, I first needed to understand what these paths were and to do that I had to define what was needed (depended upon) for any given scenario.
Oh yea, there is absolutely nothing wrong with that scenario at all. XyzzyFactory::newXyzzy relies on a global variable that is set out-of-band in the function that calls it. Foo::getXyzzy cannot set different factory settings for testing and mutates a seemingly unrelated application state variable and ruins some other downstream component’s day.
I’m a tremendous fan of dependency injection as a concept (particularly by object constructor). With dependency injection properly leveraged, not only do I understand what the bare minimum requirements are for a software component to work, but the dependencies themselves can be provided as interfaces, with their actual implementations provided by particular use cases.
Here I have achieved two benefits. Foo and XyzzyService both clearly define their outside dependencies by fetching them from a shared container. No untraceable global variables are overwritten, and I can step through this code in a debugger. I’d likely have a problem with the Foo::__construct method changing the internal state of the container’s IXyzzySettings instance, but the point is: at least I can track that down and identify when components may be altering state in a way that creates unintended consequences. Furthermore, now that the dependencies for Foo and XyzzyService are provided as interfaces, I can implement whatever state I want for IXyzzySettings. When I test Foo, I can even substitute a mock or dummy object for IXyzzyService, which leads me into mocking this container - or more specifically, automocking.
Automocking is what greatly increased my ability to quickly write tests to cover the behavior that I was converting from static and global implementations. The process went something like this: manually test the desired “hot” paths (based on the original product spec, if it existed), update the code, manually test again, lock down the behavior with a unit test, rinse, and repeat. Automocking removed the need to individually create mocks for all the possible dependencies that could exist in the container. It can be very tedious to identify all injected dependencies in an object and set them up as mocks in the event that they may be needed for a particular test. Failure to do so would often lead to null reference exceptions in the object’s constructor when just trying to initialize it for testing.
For this scenario, I only need to test Qux with different implementations of IBar, but this object can’t initialize because IFoo is not mocked and getValue is called on a null reference. That’s pretty annoying - I have to mock a dependency I don’t care about. If only someone else could do it! 😂
The following sections assume that you have checked out OpenContainer and have familiarized yourself with the library. In short, the key piece we will leverage here is the @property PHPDoc value that we use with OpenContainer to create type hint friendly container dependencies (if you have a PHP IDE with intellisense such as JetBrains PHPStorm).
1 2 3 4 5 6 7 8 9 10 11 12
usemodethirteen\OpenContainer\IContainer;
/** * in order for us to automock these properties * fully-qualified class names must be included * * @property \My\Application\IFoo $IFoo * @property \My\Application\IBar $IBar * @property \My\Application\IQux $IQux */ interfaceIApplicationContainerextendsIContainer{ }
This container interface contains type hints for all the possible dependencies that could be registered in this container. One drawback to this approach is that it takes some diligence to remember to add a @property to the interface every time a new dependency is registered in the container. Our new MockContainer will implement this interface and provide some behavior to automatically generate PHPUnit mocks for these dependencies.
/** * Register a class type * * @param string $id * @param string $class */ functionregisterType(string$id, string$class): void{ thrownew NotImplementedException(); } }
Our MockContainer uses phpDocumentor and PHPUnit to parse our container interface @property values and auto-generate mocks. In our tests, we can now MockContainer::getMock any dependency we need to set expectations on. We can use MockContainer::proxyMock to provide a concrete instance, with optional mocked properties and functions - a sort of hybrid approach that is influenced by JavaScript testing practices like spies.
publicfunctionsetUp() : void{ $this->container = new MockContainer($this); $this->container->getMock('IBar') ->expects(static::any()) ->method('getSomething') ->will(static::returnValue('123')); $this->container->proxyMock('IQux', new Qux()); }
/** * @test */ publicfunctiontest() : void{
// this test has a very specific value it needs IQux to return $this->container->getMock('IQux') ->expects(static::once()) ->method('getSomethingElse') ->will(static::returnValue('456')); } }
Applying these patterns has transformed a codebase that was responsible for a production bug nearly every week, to arguably one of the most covered with tests and most reliable in the entire platform. That level of confidence has a huge benefit on developer morale, especially on those who may be new to the codebase and are concerned with introducing bugs in an unfamiliar environment. Reliable dependency management and testing won’t ever entirely eliminate bugs (your unique production situations and data will always see to that), but it can get you very close!
]]>A way to speed up your test-driven PHP development through automation...
 Image: True Agency
Image: True Agency